Decomposition For Light-Weight Vision Models
A brief review of image decomposition methods.
Published on December 20, 2021 by Hongyi WANG
light-weight decomposition interpolation
2 min READ
Decomposition, as the most intuitive method for reducing memory cost, has been forgotten by people since it usually leads to performance degradation as well. This article reviews decomposition in deep learning and also introduces some great work in this field.
In the deep learning era, GPU plays a very important role in model training for their great parallel computing ability. However, for high-resolution real-world images, graphical memory usually tends to be insufficient. Therefore, many people use interpolation to down-sample the image. In my view, downsampling can be also viewed as a method of decomposition.
Besides downsampling, patch-sampling is another method that people use to solve the memory lacking problem. Patch-sampling refers to such a method that for every single image, firstly divides the image into several small regions with overlap, then performs segmentation on each small region separately. The final segmentation mask is the fusion of these divided smaller segmentation masks. As a typical divide-and-conquer method, patch-sampling segmentation greatly reduces memory consumption but also leads to the model training process’s lack of global context, which proves to be actually very important for better model performance. You see, many works today such as Non-Local models and vision Transformers want to model long-ranged dependencies in the network, but patches as input naturally harm the global context information.
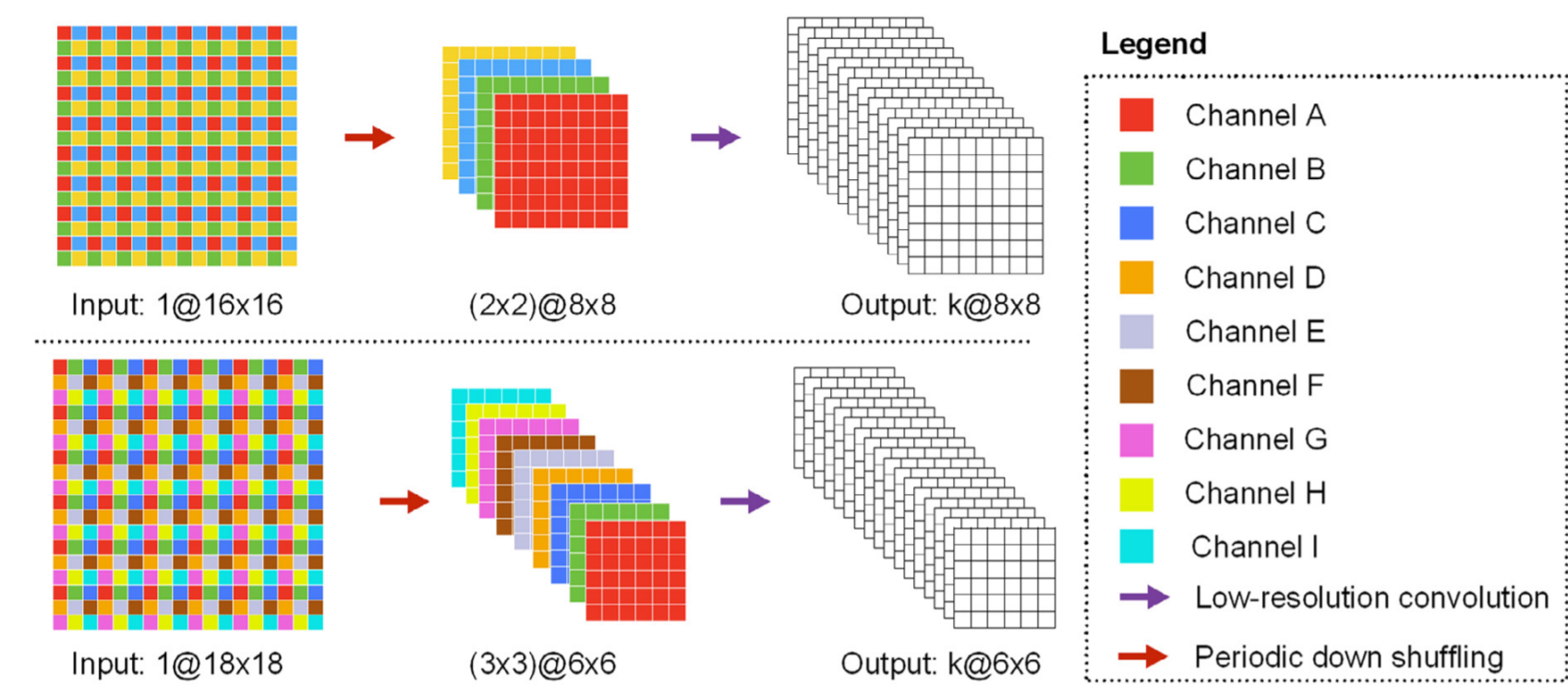
The above two ways of decomposition both cause information loss for the model. Is there a way of lossless decomposition? Actually, there is. In 2019 Medical Image Analysis, Holistic Decomposition was proposed. This method uses the inverse operation of Sub-Pixel and Sub-Pixel itself in pairs to realize low-cost patch-free segmentation.
Fig.1 Sub-Pixel
Sub-Pixel is a classic upsampling method proposed in CVPR 2016. It was originally designed for super-resolution but can also be used as a common upsampling layer. Generally speaking, it will convert several channels’ features into a bigger, single-channel image with a certain arrangement of pixels.
Fig.2 Holistic Decomposition
Holistic Decomposition is just the opposite. It will convert a single-channel image into several small images to form a multi-channel image. These two modules can be directly inserted into the front and end of existing models to realize patch-free segmentation. However, the cost is that the model’s width will shrink comparatively.
Finally, there are also other patch-free methods. Some use downsampled image as input but involve Super-Resolution to compensate for the information loss (MICCAI2021 Wang et al.); Some uses point-cloud segmentation to dynamically convert the large input image into points and omit the points with less information (MICCAI2021 Point-Unet). These methods have their pros and cons and you are encouraged to read them if interested. Currently, patch-free segmentation is still a less-noticed field that is worth further exploration.