Pooling Should Also Go Non-Local
The forgotten layer, pooling, also needs an upgrade.
Published on April 06, 2022 by Hongyi WANG
pooling transformer mlp
2 min READ
Convolution has become dominant in visual tasks for a very long time. In recent years, people have argued that convolution lacks the ability to model long-range dependencies and propose to use Non-Lcoal operations to make up for this flaw. For example, in CVPR2018, Xiaolong Wang et al. propose to use Self-Attention, which is a global-wise operation for video classification. Then, in late 2020, ViT moves a further step, proposing to use pure-transformer structure for image classification. Just a year later, people found that the old-fashioned global-wise operation, MLP, can also do the job pretty well, and that’s when MLP-mixer was proposed. Right now, more and more researchers have joined the competition of vision transformers, and the wave of non-local operations seems unstoppable.
It is undeniable that these non-local networks do gain improvements for visual tasks. However it seems that we have forgotten another important module in our networks, which is the pooling layer.
Why do we use pooling
Hinton’s classic remark “The pooling operation used in convolutional neural networks is a big mistake and the fact that it works so well is a disaster” turns out to be not so tenable, since in 2022 we can still find that pooling is still indispensable, especially for dense prediction tasks. Pooling is used to achieve invariance to image transformations, more compact representations, and better robustness to noise and clutter. Pooling can also introduce different scales of features for the network.
Pooling has stayed local
Pooling can be mainly classified into 2 categories. The first one is non-learnable pooling. Non-learnable pooling methods are the most widely used pooling methods, including max pooling and average pooling. These pooling methods downsample the input feature by a fixed pattern (such are calculating the average pixel in the window or just selecting the maximum) but also have great performance. The second category is learnable pooling. Such pooling methods are usually implemented by strided convolution (such as the one used in V-Net). These learnable pooling methods have better adaptability but may also cause instability. Our experiments have shown that non-learnable pooling can sometimes even surpass learnable pooling methods.
Problems of local-wise pooling
Consider the following situation:
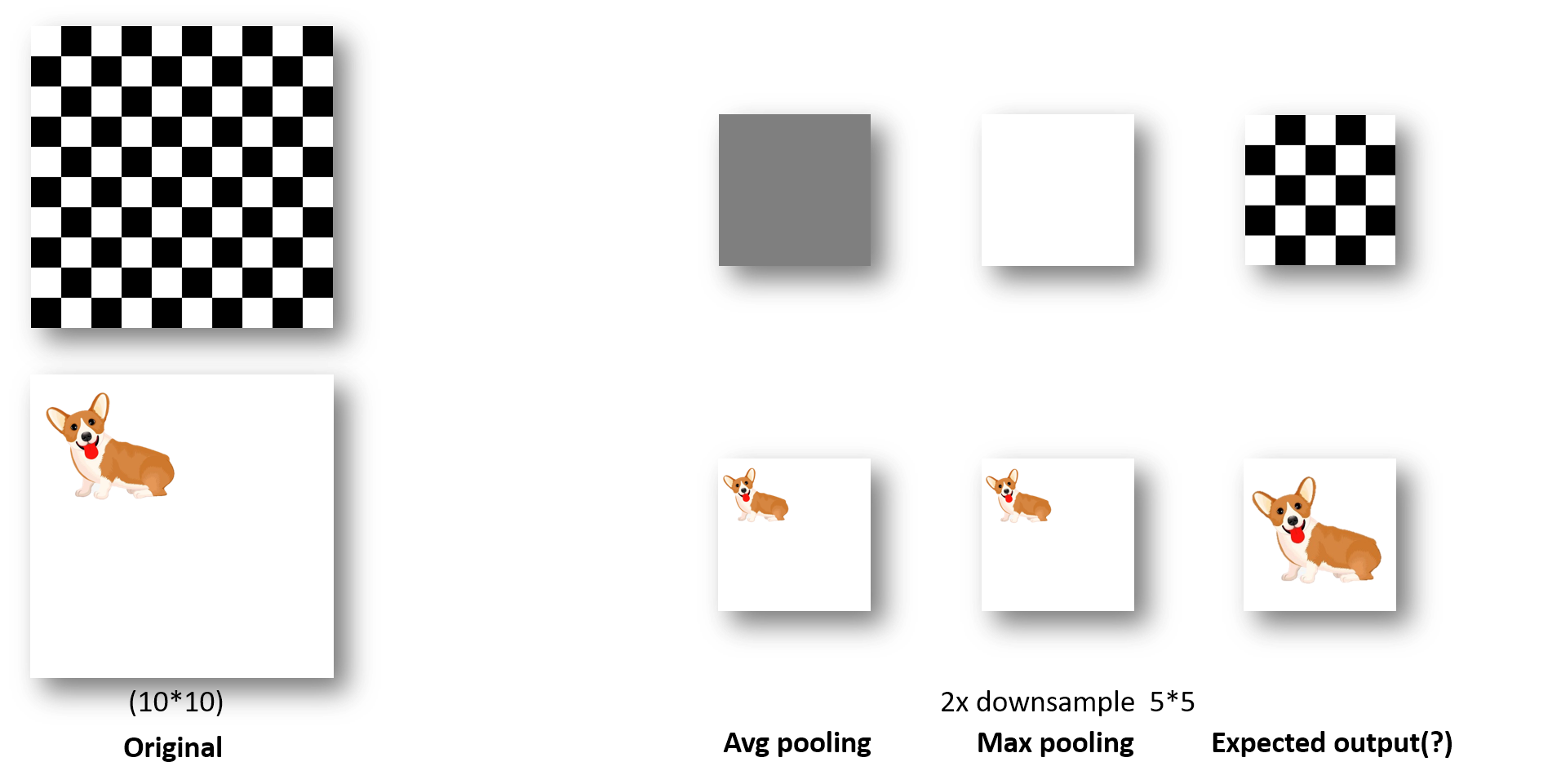
Fig.1 Example Situation
The first example is a classic chessboard image. This picture is often used to illustrate the high-frequency information loss during some image processing algorithms. As you can see, both average pooling and max pooling lose the pattern during downsampling, which may lead to unnecessary misunderstanding. The second example is a corgi in the upper left corner of an image. Though local-wise pooling can output a downsampled image, it may be better if they can focus more on the corgi rather than the background. The two problems require a global view to solve, and that’s why pooling should also go non-local just like the convolution.
We have already implemented the very first version of non-local pooling through MLP and the experimental results look really great (check it here or try it with ‘pip install nonlocalpooling’). However, such implementation inevitably leads to a dramatic increase in the number of parameters, so we still have to work on other solutions.