Pure MLP Methods And What They Are Suitable For
Pure MLP methods can do something, but maybe they are suitable for everything
Published on September 05, 2022 by Hongyi WANG
MLP classification long-range dependencies
3 min READ
Previously I have spent some time researching pure MLP-based segmentation methods. I did find some amazing work that plays all kinds of tricks on MLP, but still, I gave up on segmentation MLPs in the end. Generally speaking, MLPs are not suitable for dense prediction tasks unless some groundbreaking new architecture is proposed.
How it started
After Vision Transformers storm the Computer Vision community, people have paid more and more attention to finding ways of capturing long-range dependencies. During this time, Google realized that the very classic (or maybe “too” classic) MLP is also a global-wise operation. To solve the problem that MLP is too parameter-heavy for processing the image data, they found the way out by decoupling channel dimension and spatial dimension for separate MLP modeling. This method is termed as MLP-Mixer.
The typical pipeline of a pure MLP model
MLP-Mixer is designed for classification tasks. From the paper, we can learn that the typical pipeline of a pure-MLP network should be:
Patch-embedding to aggregate a small region into one single token. This is quite important since it can greatly reduce the spatial size of an image. For a 128*128 image, using a 8*8 patch embedding can reduce the token count from 16,384 to 256.
MLP on spatial dimension. This can be easily implemented in PyTorch by moving the spatial dimension to the last dimension.
MLP on channel dimension. Similarly, this can be implemented by moving the channel dimension to the end. Decoupling the spatial dimension and channel dimension is also quite important. For a feature with 256 sequence length and 128 channel (and let’s just assume the output shape is the same as the input), decoupling can reduce the parameter count from 1,073,741,824 to 81,920.
The pipeline works fine for classification problems, because for one image we only have to output one prediction. However, this pipeline is not suitable for segmentation tasks, because this time we have to output the predictions for every single pixel in the image, and patch-embedding already ruined much of the pixel-wise information. I have tried several methods to restore a 8*8 segmentation mask from a single token, and they all did not end up well.
But still, someone made it
It should be noted that my failed experiments do not indicate that it is impossible to segment with pure MLP models. But it is true that we have to design a new pipeline for this specific downstream task. Actually, someone has already realized it.
In ICLR 2022, Lian et al. proposed AS-MLP, which is a new MLP structure design that only requires channel mixing. It shifts the channels so that in one position there could be features from nearby tokens of nearby channels. This also means that patch-embedding becomes unnecessary since the model complexity new has nothing to do with it, which is very beneficial for dense prediction tasks such as semantic segmentation.
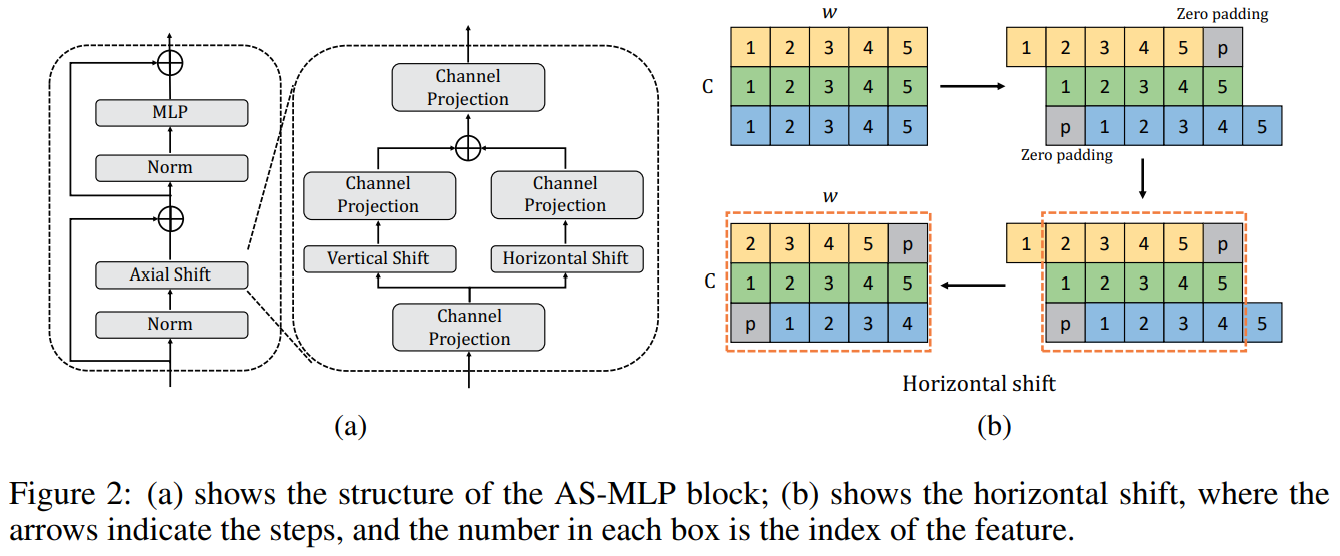
Fig.1 Demonstration of AS-MLP
I have also implemented the 3D version of it with their publicly availble codes (check here). 3D AS-MLP outperforms all the previous MLP-based methods I have tested but still cannot outperform patch-free CNNs. But whatever, I really liked this idea.